this post was submitted on 19 May 2024
131 points (100.0% liked)
Free and Open Source Software
19942 readers
163 users here now
If it's free and open source and it's also software, it can be discussed here. Subcommunity of Technology.
This community's icon was made by Aaron Schneider, under the CC-BY-NC-SA 4.0 license.
founded 3 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
Anyone found the specific numbers of acceptance rate with in comparison to no knowledge of the gender?
On researchgate I only found the abstract and a chart that doesn't indicate exactly which numbers are shown.
edit: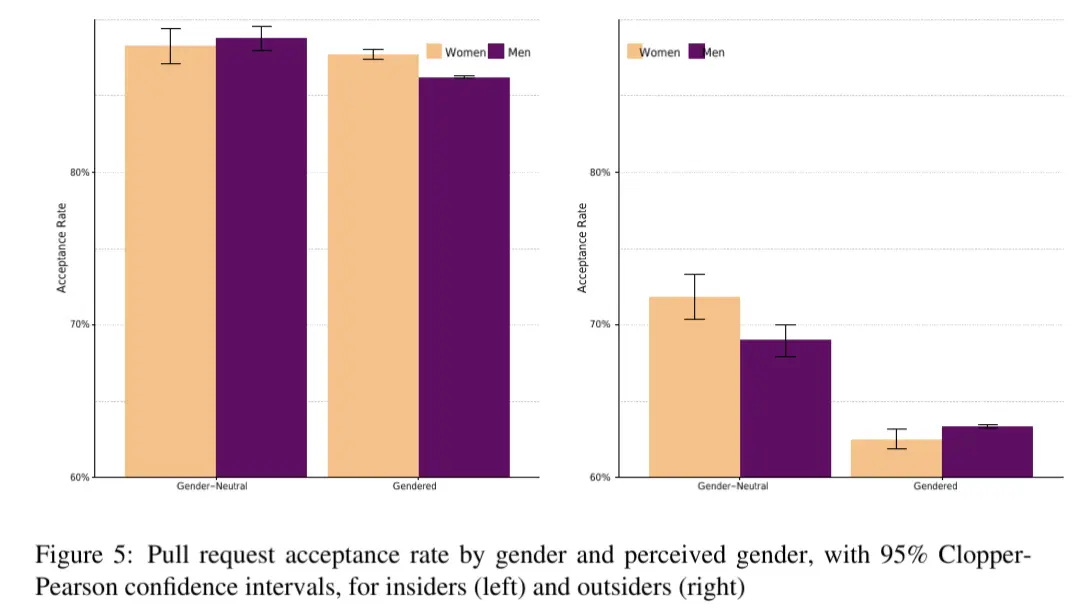
Interesting for me is that not only women but also men had significantly lower accepance rates once their gender was disclosed. So either we as humans have a really strange bias here or non binary coders are the only ones trusted.
edit²:
I'm not sure if I like the method of disclosing people's gender here. Gendered profiles had their full name as their user name and/or a photography as their profile picture that indicates a gender.
So it's not only a gendered VS. non-gendered but also a anonymous VS. indentified individual comparison.
And apparantly we trust people more if we know more about their skills (insiders rank way higher than outsiders) and less about the person behind (pseudonym VS. name/photography).
Thanks for grabbing the chart.
My Stats 101 alarm bells go off whenever I see a graph that does not start with 0 on the Y axis. It makes the differences look bigger than they are.
The 'outsiders, gendered' which is the headline stat, shows a 1% difference between women and men. When their gender is unknown there is a 3% difference in the other direction (I'm just eyeballing the graph here as they did not provide their underlying data, lol wtf ). So, overall, the sexism effect seems to be about 4%.
That's a bit crap but does not blow my hair back. I was expecting more, considering what we know about gender pay gaps, etc.
...or the research is flawed. Gender identity was gained from social media accounts. So maybe it's a general bias against social media users (half joking).
I think (unless I misunderstood the paper), they only included people who had a Google+ profile with a gender specified in the study at all (this is from 2016 when Google were still trying to make Google+ a thing).
Perhaps ppl who keep their githubs anonymous simply tend to be more skilled. Older, more senior devs grew up in an era where social medias were anonymous. Younger, more junior devs grew up when social medias expect you to put your real name and face (Instagram, Snapchat, etc.).
More experienced devs are more likely to have their commits accepted than less experienced ones.
We ass-u-me too much based on people's genders/photographs/ideas/etc., which taints our objectivity when assessing the quality of their code.
For a close example on Lemmy: people refusing to collaborate with "tankie" devs, with no further insight on whether the code is good or not.
There also used to be code licensed "not to be used for right wing purposes", and similar.
That's not an excellent example. If they refuse to collaborate with them, and also don't make any claims about the quality of code, then the claim that their objectivity in reviewing code is tainted doesn't hold.
Their objectivity is preempted by a subjective evaluation, just like it would be by someone's appearance or any other perception other than the code itself.
Page 15
~Anti~ ~Commercial-AI~ ~license~ ~(CC~ ~BY-NC-SA~ ~4.0)~
Thank you. Unfortunately, your link doesn't work either - it just leads to the creative commons information). Maybe it's an issue with Firefox Mobile and Adblockers. I'll check it out later on a PC.
Looking at their comment history they seem to allways include that link to the CC license page in some attempt to prevent the comments from being used with AI.
I have no idea of if that is actually a thing or just a fad, but that was the link.
Thanks for pointing that out.
Seems like a wild idea as... a) it poisons the data not only for AI but also real users like me (I swear I'm not a bot :D). b) if this approach is used more widely, AIs will learn very fast to identify and ignore such non-sense links and probably much faster than real humans.
It sounds like a similar concept as captchas which annoy real people, yet fail to block out bots.
Yeah, that is my take as well, at first I thought it was completely useless just like the old Facebook posts with users posting a legaliese sounding text on their profile trying to reclaim rights that they signed away when joining facebook, but here it is possible that they are running their own instance so there is no unified EULA, which gives the license thing a bit more credibillity.
But as you say, bots will just ignore the links, and no single person would stand a chance against big AI with their legal teams, and even if they won the AI would still have been trained on their data, and they would get a pittance at most.
Page 15 of the pdf has this chart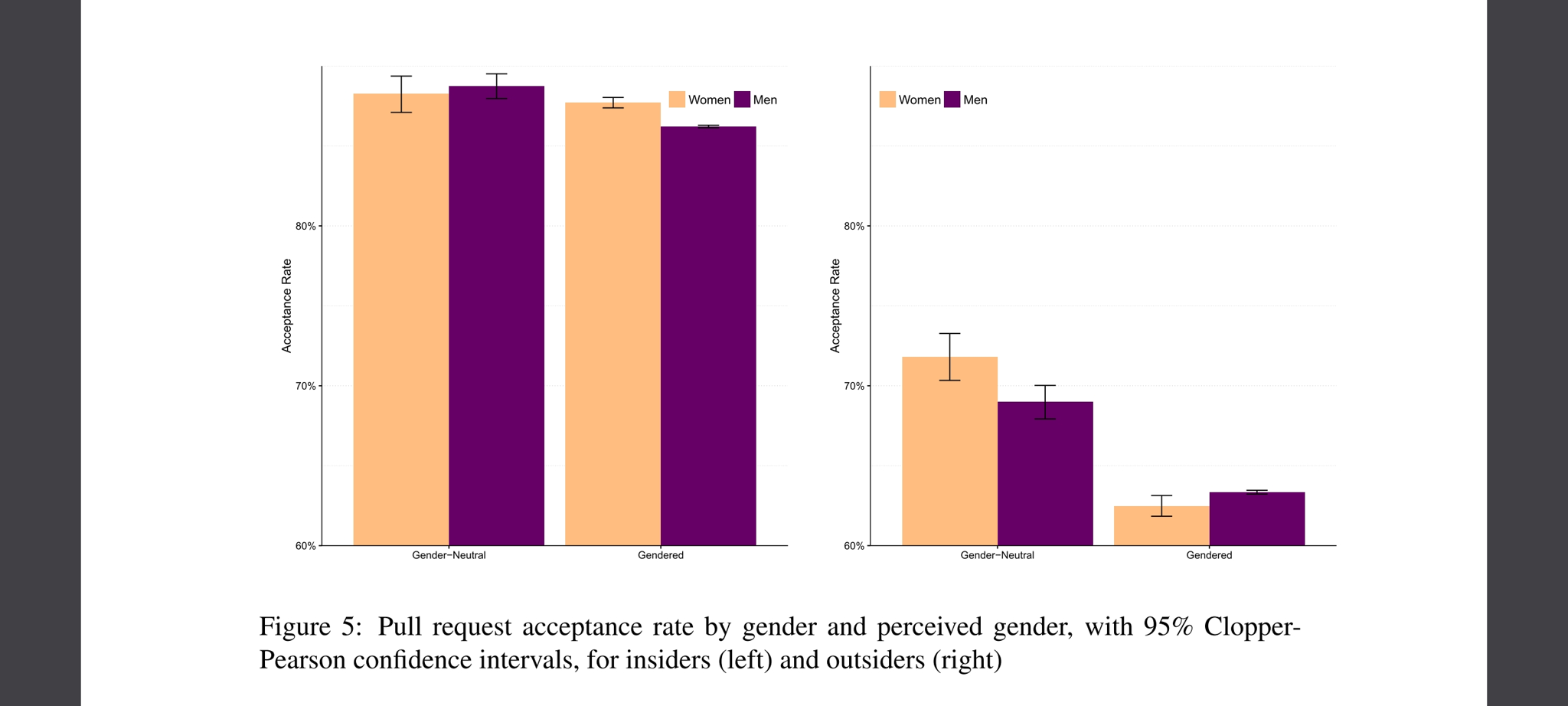
(note the vertical axis starts at 60% acceptance rate)
60% acceptance rate baseline? Doubt!
Their link wasn't to the paper but to the license to poison possible AIs training their models on our posts. Idk if that actually is of any use though
How does a photograph disclose someone's gender?
The study differentiates between male and female only and purely based on physical features such as eye brows, mustache etc.
I agree you can't see one's gender but I would say for the study this can be ignored. If you want to measure a bias ('women code better/worse than men'), it only matters what people believe to see. So if a person looks rather male than female for a majority of GitHub users, it can be counted as male in the statistics. Even if they have the opposite sex, are non-binary or indentify as something else, it shouldn't impact one's bias.
Through gender stereotypes. The observer's perception is all that counts in this case anyways.