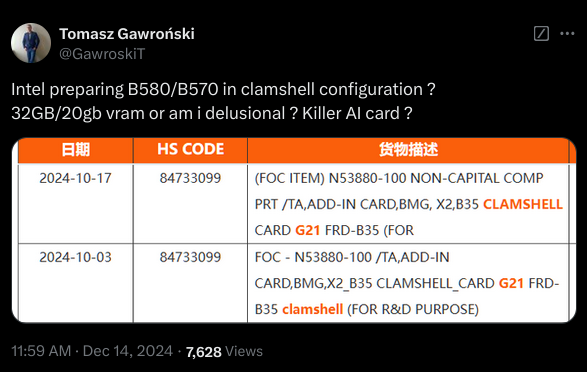
Maybe even 32GB if they use newer ICs.
More explanation (and my source of the tip): https://www.pcgamer.com/hardware/graphics-cards/shipping-document-suggests-that-a-24-gb-version-of-intels-arc-b580-graphics-card-could-be-heading-to-market-though-not-for-gaming/
Would be awesome if true, and if it's affordable. Screw Nvidia (and, inexplicably, AMD) for their VRAM gouging.

{kind=link}