You will likely still hear the cell broadcast. Alerts of this level make every phone give off a piercing sound and even if your phone is dead, you will hear it from your neighbours' because it's loud.
with regard/respect to
Whoever told you text is expensive to draw has no idea what they're talking about.
Well you're both wrong and right.
This appears to be a clone of the Brompton front rack mount. I don't thing that's an open spec but it's so wide-spread that it's pretty standard.
Specifically this section:
Why is Magic Earth free? What is the business model?
Magic Earth is free for all our end-users but we also have a paid Magic Earth SDK for business partners. For instance Selectric.de (a supplier for navigation solutions for ambulances and fire trucks), Smarter AI (developing ADAS systems) or Absolute Cycling (using the platform on bicycles). For more info on the SDK, you can check magiclane.com.
No terminal emulator ever should affect the performance of the rest of your system.
I mean that totally w.r.t. how it feels to interact with the terminal emulator.
A screencast cannot really capture that. Practically any terminal is fast enough to render a shitton of text quickly and "smoothly".
The difference in speed can only really be felt.
W.r.t. UI, it looks exactly like you'd expect a GTK4/adwaita terminal emulator to look.
Unless you frequently build this from source, you don't need to care about the pandoc build-time dep.
IME it feels much snappier than foot.
I mean, it's a terminal emulator; what's it supposed to show, a bunch of white text on black background?
The problem with xterm is that everything else about it sucks. The only other half-decent performer is mlterm which is decent but has its share of issues.
This one feels quite snappy; better than foot.
Chill, it's just pandoc.
7
Feb 27, 2024 - Bangs upgrades, user control enhancements, and colour code widget #
Features
- We've made further progress in enhancing Bangs in the UI. And following the release of our open-source bags repository, the community has contributed by adding and fixing dozens of bangs already! Additionally, we upgraded all bangs to use HTTPS where possible.

- To further enhance user control, we now indicate when there are blocked results for your search queries #2698 @Fernandez)

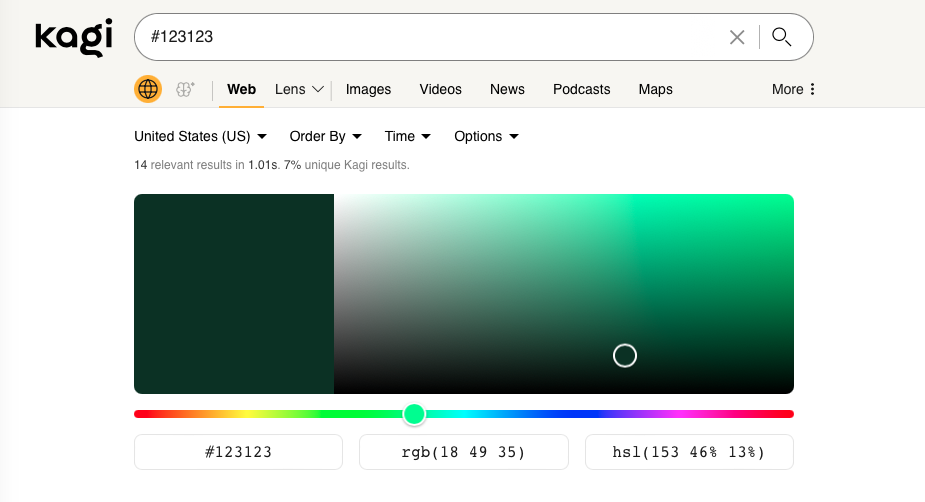
- We've introduced a new colour code search widget. It displays the selected colour, allows to pick an alternative, and to convert between HSL and RGB formats #118 @yokoffing)
Kagi for Safari 2.2.2
- If you were having issues with Kagi for Safari, make sure you are running the latest version and that 'Engine to redirect' option in extension settings is set to the one used by Safari.
- [Changed] Adopted monochrome icon for toolbar/menu to match Safari icon styles
Improvements and bug fixes
- Kagi Quick Answer now remembers 'Show more" option #3241 @Dustin
- We've introduced a new progress animation for the Assistant's responses (please note, the Assistant remains in beta and limited to Ultimate subscribers)
- Include non-US universities in Academic lens #3303 @rainfallwaterfallweb
- Automatic Kagi Status Page Updates #2914 @happinessattack
- Quotes cannot be used with assistant? #3276 @cardinal086
- Quick answer freezes page #3237 @repelz
- LLM Model Help Chart - Add Cost and Context Window #3049 @CrunchyFritos
- Error summarizing Von Neumann PDF #2978 @CrunchyFritos
- Universal Summarizer on iOS should not scroll horizontally #3251 @equalidea
- Site: search shows fewer results with "personalization" turned off #3040 @Value7609
- Broken search dropdowns #3278 @val
- PDFs appear in image search #3289 @matteoscopel
- Quick Peek breaks with "[ CDATA" in question #3308 @paszek
- Taiwan(tw) bang is missing in region search #3287 @fc
- Site: search shows fewer results with "personalization" turned off #3040 @Value7609
- Jisho bang encodes spaces incorrectly #3245 @adamaveray
- Changelog formatting broken for lists #3280 @VIEWVIEWVIEW
8
Announcements
-
Kagi Bangs repository is now open source (thanks @Browsing6853 for suggesting this in #481). You can now refine the accuracy of existing bangs or introduce new ones for everyone to enjoy on Kagi Search. Your contributions will enhance the search experience for users worldwide.
-
Fresh from Kagi Labs: We're shipping an alpha version of Kagi Sidekick, a search and "chat with content" solution for websites.
Kagi Sidekick will offer instant site search results, and on-demand AI generated summaries, by tapping directly into the website's content. As a bonus, the website content will automatically (after opt-in) surface as a part of Kagi search index.
You can see Sidekick live in action in Kagi's documentation.
We'd love to hear your feedback, and how would you use it on your website. We will plan the launch based on incoming demand.
Visit the Sidekick project landing page to learn more and register your interest for a beta invite. If you'd like to participate in building projects like this, Kagi Labs is hiring part-time contributors.
Improvements & Bug fixes
- Faster and enhanced autocomplete in Kagi Maps
- We added the option to disable Quick Answers through your Search Settings #3185 @TyrelSouza
- You can now turn off Kagi's changelog notifications in Account Settings #2722 @ChristenGottschlich
- Found a query that returns no results #3147 @rossdanderson
- Completely unrelated search result #3248 @raphael
- Weird/unrelated result from search query #3173 @arcaneasada
- Images fail to load from various sources with a 404 in Assistant #3154 @rtwk
- "Summarize in Document Language" detecting the wrong language #3202 @lou
- AI Research Assistant does not always provide sources #3138 @cmooon
- Discuss Url has a display bug #3081 @unruffled5088
- UX: Cannot untoggle image search filters. #3168 @Chris
- Summarize page is broken for every quora result #3149 @Browsing6853
- Add hyperlink at wolfram alpha instant answers to wolfram alpha website #3195 @Browsing6853
- Time converter is buggy #3180 @Oni-giri
- Quick Peek on iOS missing foldable arrow graphics #3158 @equalidea
- Inline images should not scroll vertically on iOS #3159 @equalidea
- Add a "Remove results from this site" in dropdown to temporarily remove said site from showing up in results #3019 @FurbyOnSteroids
- Better expose bangs #2940 @leftium
- Lenses with glob exclude doesn't work #3157 @Orhideous
- Bangs regarding fedora package search are broken #3234 @strom
- Tldr bang redirects to offline page #3230 @stzsch
- Image search is surfacing non-free licensed images, despite license filters #2964 @KagiForMe
- Jarring truncated quick answer text #3210 @Jake-Moss
- Add table borders to assistant outputs #3200 @platyhsu
- Can't select text in kagi summarizer textbox #3175 @Value7609
- Shouldn’t Options - Options really be “Personalized results” #3033 @stoyle
- When navigating images they are in bad resolution for a second or so until they become sharp #3242 @eltaco
- Open search bar icon doesn't pop up on Mobile #3258 @sefidel
- Kagi persists old query when switching from web to image results #3226 @iivvoo
$_latex_inlinein quick answer #3225 @bert
Modern thorium reactors don't exist on the power grid.