I wish we had 5 minute headways haha.
RagingHungryPanda
joined 2 years ago
Thanks for giving it a good read through! If you're getting on nvme ssds, you may find some of your problems just go away. The difference could be insane.
I was reading something recently about databases or disk layouts that were meant for business applications vs ones meant for reporting and one difference was that on disk they were either laid out by row vs by column.
Thanks haha
That was a bit of a hasty write, so there's probably some issues with it, but that's the gist
yes? maybe, depending on what you mean.
Let's say you're doing a job and that job will involve reading 1M records or something. Pagination means you grab N number at a time, say 1000, in multiple queries as they're being done.
Reading your post again to try and get context, it looks like you're identifying duplicates as part of a job.
I don't know what you're using to determine a duplicate, if it's structural or not, but since you're running on HDDs, it might be faster to get that information into ram and then do the job in batches and update in batches. This will also allow you to do things like writing to the DB while doing CPU processing.
BTW, your hard disks are going to be your bottleneck unless you're reaching out over the internet, so your best bet is to move that data onto an NVMe SSD. That'll blow any other suggestion I have out of the water.
BUT! there are ways to help things out. I don't know what language you're working in. I'm a dotnet dev, so I can answer some things from that perspective.
One thing you may want to do, especially if there's other traffic on this server:
- use WITH (NOLOCK) so that you're not stopping other reads and write on the tables you're looking at
- use pagination, either with windowing or LIMIT/SKIP to grab only a certain number of records at a time
Use a HashSet (this can work if you have record types) or some other method of equality that's property based. Many Dictionary/HashSet types can take some kind of equality comparer.
So, what you can do is asynchronously read from the disk into memory and start some kind of processing job. If this job does also not require the disk, you can do another read while you're processing. Don't do a write and a read at the same time since you're on HDDs.
This might look something like:
offset = 0, limit = 1000
task = readBatchFromDb(offset, limit)
result = await task
data = new HashSet\<YourType>(new YourTypeEqualityComparer()) // if you only care about the equality and not the data after use, you can just store the hash codes
while (!result.IsEmpty) {
offset = advance(offset)
task = readBatchFromDb(offset, limit) // start a new read batch
dataToWork = data.exclusion(result) // or something to not rework any objects
data.addRange(result)
dataToWrite = doYourThing(dataToWork)
// don't write while reading
result = await task
await writeToDb(dataToWrite) // to not read and write. There's a lost optimization on not doing any cpu work
}
// Let's say you can set up a read or write queue to keep things busy
abstract class IoJob {
public sealed class ReadJob(your args) : IoJob
{
Task\<Data> ReadTask {get;set;}
}
public sealed class WriteJob(write data) : IoJob
{
Task WriteTask {get;set;}
}
}
Task\<IoJob> executeJob(IoJob job){
switch job {
ReadJob rj => readBatchFromDb(rj.Offset, rj.Limit), // let's say this job assigns the data to the ReadJob and returns it
WriteJob wj => writeToDb(wj) // function should return the write job
}
}
Stack\<IoJob> jobs = new ();
jobs.Enqueue(new ReadJob(offset, limit));
jobs.Enqueue(new ReadJob(advance(offset), limit)); // get the second job ready to start
job = jobs.Dequeue();
do () {
// kick off the next job
if (jobs.Peek() != null) executeJob(jobs.Peek());
if (result is ReadJob rj) {
data = await rj.Task;
if (data.IsEmpty) continue;
jobs.Enqueue(new ReadJob(next stuff))
dataToWork = data.exclusion(data)
data.AddRange(data)
dataToWrite = doYourThing(dataToWork)
jobs.Enqueue(new WriteJob(dataToWrite))
}
else if (result is WriteJob wj) {
await writeToDb(wj.Data)
}
} while ((job = jobs.Dequeue()) != null)

I've got Idrive backups at 5TB for like $5 a month or something.
And they PAID to be there!
Oh that's dope. How many hours are you running? Do you also use them for things like encoding or something like that?
Sweet!
What's up is everything I've been running and down is what I haven't.
not working
I haven't been able to get friendica to connect to Maria DB, so I'll eventually try just MySql. Grafana isn't running bc I would need to change a lot of things to get an exporter into each container and the truenas apps don't really allow that configuration - fine if you have docker compose though, which I've started doing more and more.
new
I just got up and running with Stirling pdf, a free (and paid) PDF editor. That looks pretty sweet.
But I'm now also using 15GB of the 32 on the system, which is still plenty for Arc cache for me
what I want
I want to rent a VPS to host various fediverse apps, probably Lemmy, pixelfed, and write freely to start, for the nomad/expect communities. I've been looking at netcup and they have some decent arm offerings.
I'd like to put Talos Linux on it so I can get some kubernetes experience. They have a good sized server for €10, so I could expand to add a DB server or one specifically for logging and metrics.
I was looking at Hetzner, but I've read that their block storage is super slow and causes timeouts on DB.
Of course, can I even run these apps on arm? I guess I gotta find that out.
One thing I'd like to do is make a web page that makes signups super easy and would create an account on all services, ideally. Not a huge deal of that isn't reasonable, but it'd be nice to allow doing it once rather than multiple times. If I could get sso, that'd be good, but I don't know how supported that is.
I'm actually watching a video about that, complete with studies and everything.
15
What Airlines Don't Want You To Know: How They Keep Prices High - More Perfect Union
(www.youtube.com)
69
Book Review: Fifty years later, Ursula K. Le Guin’s Novel about Utopian Anarchists Is as Relevant as Ever
(www.scientificamerican.com)
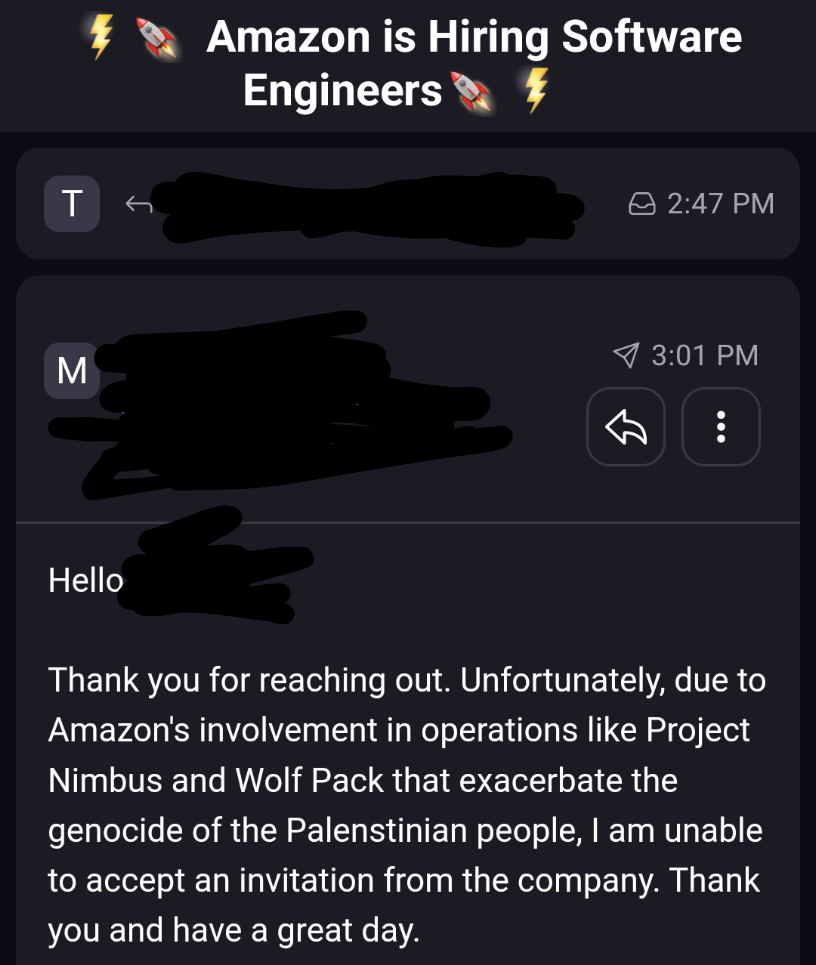
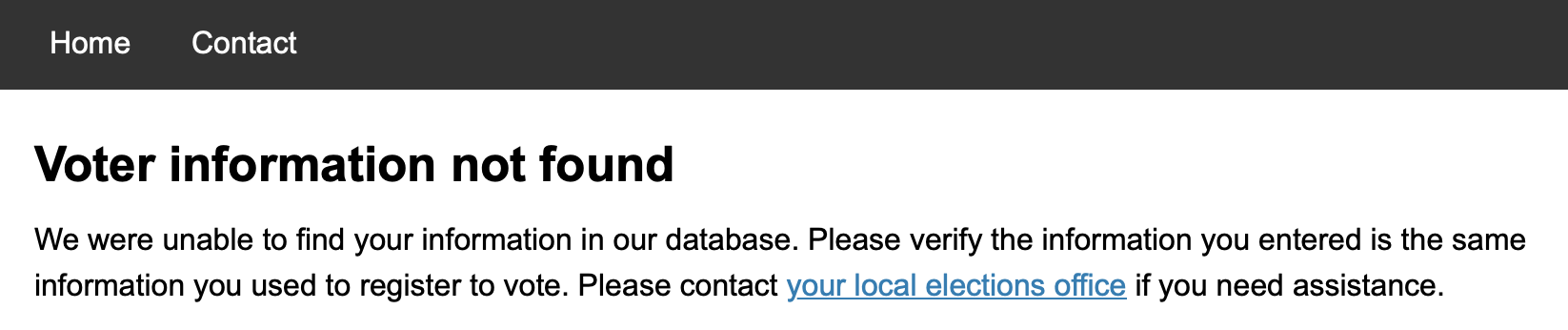
Edit/Update: It turns out that my last name has a capitol letter in the middle and they put a space in it. Thank god. I can actually vote this year.
I've been saving all of these today. Thanks a bunch!