I'd never heard of this list, so thanks for sharing. I have to say while some of the projects seem to have been included due to minor offences, I'm really disappointed in some of my favourite FOSS projects.
danielquinn
joined 2 years ago
I didn't understand what you meant by Joplin not being "fully FOSS", so I went looking for the license. Is really quite strange. Basically they've used a "personal license" for some parts and the AGPL for the rest. That's... annoying.
Perhaps, but we shouldn't subsidise burning the planet.
Seems to me that the answer here should be a substantial tax on petrol.
Every now and then I need to make a presentation, and LibreOffice Impress to Microsoft PowerPoint isn't that good. I resort to Google Slides for now.
It may not be your thing, but personally I've had a lot of success with RevealJS. You just write HTML (or even Markdown) and it automatically builds your slides for you such that they run on any browser. You can make it as complicated or as simple as you like (I've done some wild stuff with CSS) and everything can be versioned in git and published to anywhere that supports static files.
Here's a reasonably professional-looking presentation I occasionally give about Kubernetes if you're interested.
Are you using GNOME? If so, I remember there being an extension for that.
You might like Krita a little more. It's far more powerful than Paint, but its interface is very familiar.
That's a very low bar.
I would be less concerned about the GPU driver and more about the entire distro. Like most distros, Ubuntu has a release cycle where versions of everything are deprecated over time in favour of newer ones, and to expect that the entire OS will be fully supported in 10 years may be asking a bit much (I'm not sure if even their LTS release goes that far).
On top of that, Ubuntu could go bankrupt or get bought out, or simply enshittify (more than it already has) in that time. Expecting Ubuntu specifically to be supported on your laptop in ten years is anyone's guess.
However, what you can be reasonably sure of is that Linux will continue to support your system, GPU and all, for a very long time. I heard a kernel developer once say that due to the kernel's modular design, there's support in there for stuff just one or two people in the whole world use.
As someone else has already pointed out, FOSS support for hardware generally gets better over time, and a GTX video card is ubiquitous. There's going to be a hell of a lot of those floating around on laptops, servers, and homelabs for a lot more than ten years.
You just might not be able to stick with Ubuntu. The older the hardware, the more you might have to lean toward the more technical distros that make it easy to customise the kernel or that favour old hardware. I like Gentoo for this job, but even Ubuntu or Debian have paths to do compile your own kernel for example.
Granted, Rutte is a sycophantic brown noser, but did he actually say that? I watched the whole ridiculous clip and didn't notice that quote.

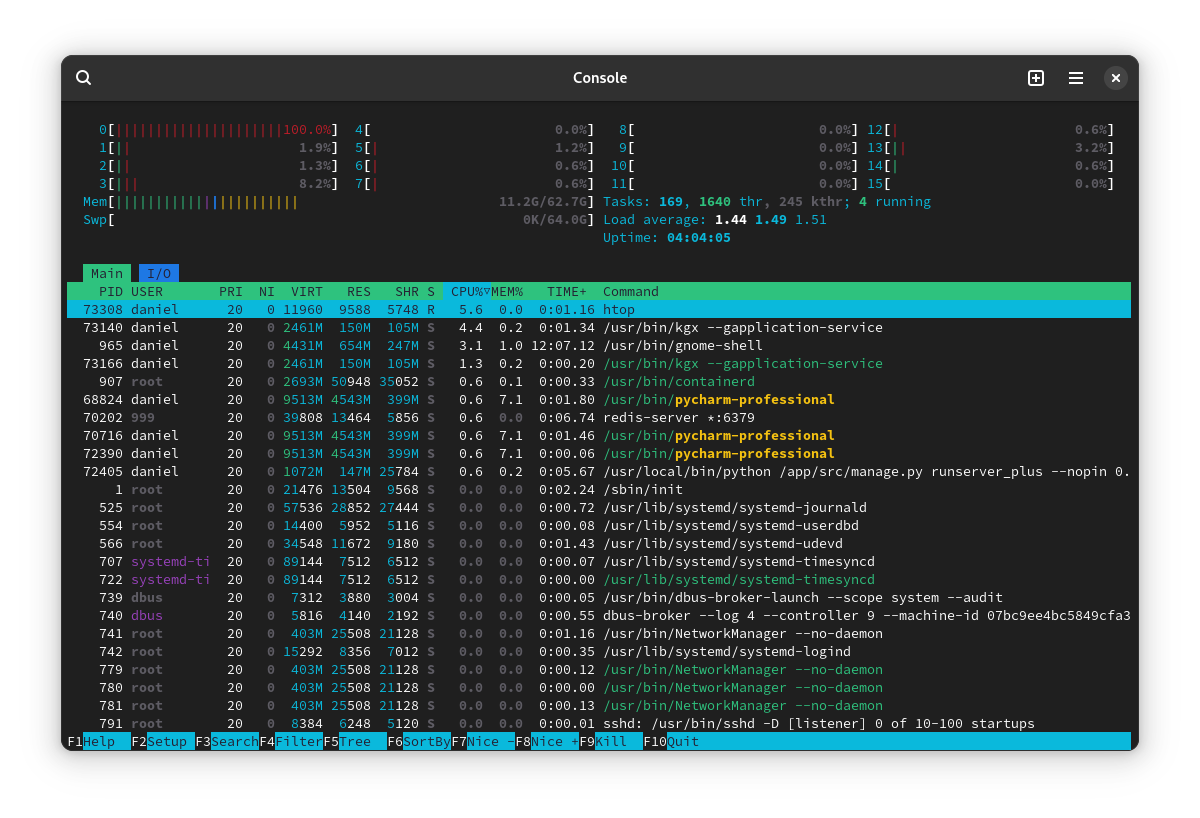
From time to time, often after I've restored from sleep or finished playing a Steam game, one of my CPU cores is pinned at 100% with no indication of what might be doing it. Running htop, btop, or GNOME system monitor all show the same thing: CPU0 at 100% while the rest are doing near-nothing, and no process in particular seems to be using those resources.
If I restart, it's back to normal, and sometimes I can play a game in Steam or let the computer go to sleep and it doesn't do this, but it happens often enough that's annoying/confusing so I'd like to know if there's a way to either (a) diagnose which processes are using which CPU cores, or (b) somehow "reset" the checking of these values to make sure that something's not just being misreported.
This is a desktop system running Arch & GNOME.
view more: next ›
I used to get very upset by this, but I've taken great solace in seeing how their power and influence are waning.